tick.linear_model.ModelSmoothedHinge¶
- class tick.linear_model.ModelSmoothedHinge(fit_intercept: bool = True, smoothness: float = 1.0, n_threads: int = 1)[source]¶
Smoothed hinge loss model for binary classification. This class gives first order information (gradient and loss) for this model and can be passed to any solver through the solver’s
set_modelmethod.Given training data \((x_i, y_i) \in \mathbb R^d \times \{ -1, 1 \}\) for \(i=1, \ldots, n\), this model considers a goodness-of-fit
\[f(w, b) = \frac 1n \sum_{i=1}^n \ell(y_i, b + x_i^\top w),\]where \(w \in \mathbb R^d\) is a vector containing the model-weights, \(b \in \mathbb R\) is the intercept (used only whenever
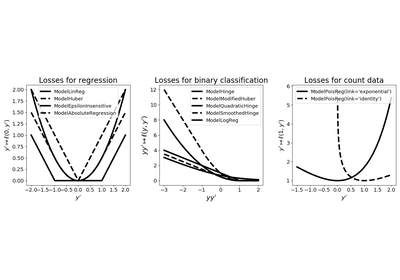
fit_intercept=True) and \(\ell : \mathbb R^2 \rightarrow \mathbb R\) is the loss given by\[\begin{split}\ell(y, y') = \begin{cases} 1 - y y' - \frac \delta 2 &\text{ if } y y' \leq 1 - \delta \\ \frac{(1 - y y')^2}{2 \delta} &\text{ if } 1 - \delta < y y' < 1 \\ 0 &\text{ if } y y' \geq 1 \end{cases}\end{split}\]for \(y \in \{ -1, 1\}\) and \(y' \in \mathbb R\), where \(\delta \in (0, 1)\) can be tuned using the
smoothnessparameter. Note that \(\delta = 0\) corresponds to the hinge loss. Data is passed to this model through thefit(X, y)method where X is the features matrix (dense or sparse) and y is the vector of labels.- Parameters:
fit_intercept :
boolIf
True, the model uses an interceptsmoothness :
double, default=1.The smoothness parameter used in the loss. It should be > 0 and <= 1 Note that smoothness=0 corresponds to the Hinge loss.
n_threads :
int, default=1 (read-only)Number of threads used for parallel computation.
if
int <= 0: the number of threads available on the CPUotherwise the desired number of threads
- Attributes:
features : {
numpy.ndarray,scipy.sparse.csr_matrix}, shape=(n_samples, n_features)The features matrix, either dense or sparse
labels :
numpy.ndarray, shape=(n_samples,) (read-only)The labels vector
n_samples :
int(read-only)Number of samples
n_features :
int(read-only)Number of features
n_coeffs :
int(read-only)Total number of coefficients of the model
dtype :
{'float64', 'float32'}, default=’float64’Type of the data arrays used.