tick.hawkes.HawkesSumExpKern¶
- class tick.hawkes.HawkesSumExpKern(decays, penalty='l2', C=1000.0, n_baselines=1, period_length=None, solver='agd', step=None, tol=1e-05, max_iter=100, verbose=False, print_every=10, record_every=10, elastic_net_ratio=0.95, random_state=None)[source]¶
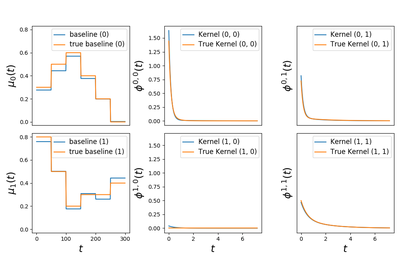
Hawkes process learner for sum-exponential kernels with fixed and given decays, with many choices of penalization and solvers.
Hawkes processes are point processes defined by the intensity:
\[\forall i \in [1 \dots D], \quad \lambda_i(t) = \mu_i(t) + \sum_{j=1}^D \sum_{t_k^j < t} \phi_{ij}(t - t_k^j)\]where
\(D\) is the number of nodes
\(\mu_i(t)\) are the baseline intensities
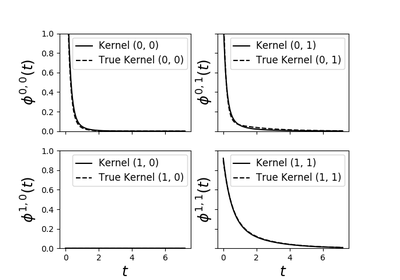
\(\phi_{ij}\) are the kernels
\(t_k^j\) are the timestamps of all events of node \(j\)
and with an sum-exponential parametrisation of the kernels
\[\phi_{ij}(t) = \sum_{u=1}^{U} \alpha^u_{ij} \beta^u \exp (- \beta^u t) 1_{t > 0}\]In our implementation we denote:
Integer \(D\) by the attribute
n_nodesInteger \(U\) by the attribute
n_decaysVector \(\mu \in \mathbb{R}^{D}\) by the attribute
baselineMatrix \(A = (\alpha^u_{ij})_{ij} \in \mathbb{R}^{D \times D \times U}\) by the attribute
adjacencyVector \(\beta \in \mathbb{R}^{U}\) by the parameter
decays. This parameter is given to the model
- Parameters:
decays :
np.ndarray, shape=(n_decays, )The decays used in the exponential kernels.
n_baselines :
int, default=1In this hawkes learner baseline is supposed to be either constant or piecewise constant. If
n_baseline > 1then piecewise constant setting is enabled. In this case \(\mu_i(t)\) is piecewise constant on intervals of sizeperiod_length / n_baselinesand periodic.period_length :
float, default=NoneIn piecewise constant setting this denotes the period of the piecewise constant baseline function.
C :
float, default=1e3Level of penalization
penalty : {‘l1’, ‘l2’, ‘elasticnet’, ‘none’} default=’l2’
The penalization to use. Default is ridge penalization.
solver : {‘gd’, ‘agd’, ‘bfgs’, ‘svrg’}, default=’agd’
The name of the solver to use
step :
float, default=NoneInitial step size used for learning. Used in ‘gd’, ‘agd’, ‘sgd’ and ‘svrg’ solvers
tol :
float, default=1e-5The tolerance of the solver (iterations stop when the stopping criterion is below it). If not reached the solver does
max_iteriterationsmax_iter :
int, default=100Maximum number of iterations of the solver
verbose :
bool, default=FalseIf
True, we verbose things, otherwise the solver does not print anything (but records information in history anyway)print_every :
int, default=10Print history information when
n_iter(iteration number) is a multiple ofprint_everyrecord_every :
int, default=10Record history information when
n_iter(iteration number) is a multiple ofrecord_everyelastic_net_ratio :
float, default=0.95Ratio of elastic net mixing parameter with 0 <= ratio <= 1.
For ratio = 0 this is ridge (L2 squared) regularization.
For ratio = 1 this is lasso (L1) regularization.
For 0 < ratio < 1, the regularization is a linear combination of L1 and L2.
Used in ‘elasticnet’ penalty
random_state : int seed, or None (default)
The seed that will be used by stochastic solvers. If
None, a random seed will be used (based on timestamp and other physical metrics). Used in ‘sgd’, and ‘svrg’ solvers- Attributes:
n_nodes :
intNumber of nodes / components in the Hawkes model
baseline :
np.array, shape=(n_nodes,)Inferred baseline of each component’s intensity
adjacency :
np.ndarray, shape=(n_nodes, n_nodes, n_decays)Inferred adjacency matrix
coeffs :
np.array, shape=(n_nodes + n_nodes * n_nodes * n_decays, )Raw coefficients of the model. Row stack of
self.baselineandself.adjacency